In an era where information is king, the ability to convert spoken words into written text accurately is invaluable. Whether you're a content creator, a transcriptionist, a researcher, or simply someone looking to save time on note-taking, OpenAI's Whisper offers a powerful solution for speech-to-text transcription. In this comprehensive guide, we will walk you through the process of harnessing the capabilities of OpenAI Whisper to transcribe spoken language into written text with ease and precision.
Introduction to OpenAI's Whisper
Speech-to-text transcription has become an integral part of our digital lives. From transcribing interviews and meetings to generating captions for videos and podcasts, the demand for reliable and efficient transcription tools has never been higher. OpenAI, a leader in the field of artificial intelligence, has developed Whisper, an advanced Automatic Speech Recognition (ASR) system that excels at converting spoken language into written text. This article will serve as your roadmap to understanding and utilizing Whisper effectively.
Why Whisper Matters
Before we dive into the details of how to use OpenAI Whisper, let's take a moment to appreciate why it matters. Accurate speech-to-text transcription has a wide range of applications across various industries:
Content Creation: Content creators can save hours of manual transcription work when converting recorded interviews or podcasts into written articles.
Accessibility: Whisper aids in making digital content more accessible to individuals with hearing impairments by providing accurate captions for videos and audio content.
Research: Researchers can easily transcribe interviews, focus group discussions, and surveys, allowing for better analysis and data interpretation.
Legal Services: In the legal field, court proceedings and depositions can be transcribed swiftly, aiding in case documentation and review.
Healthcare: Medical professionals can efficiently transcribe patient notes, ensuring accurate and detailed records.
Education: Educators can provide students with accessible lecture transcripts, enhancing the learning experience.
Finance: Financial analysts can transcribe earnings calls, helping them track and analyze financial information effectively.
With these diverse applications, the demand for reliable and high-quality speech-to-text transcription tools like OpenAI Whisper has never been greater. In the sections that follow, we'll explore two methods to use Whisper and provide insights into how you can maximize its accuracy and address its limitations.
Method 1: Use Anakin AI's No Code App Builder
Step 1: Access the Anakin AI No Code App Builder
Visit the Anakin AI website and sign up for an account if you haven't already.
Once logged in, navigate to the No Code App Builder section.
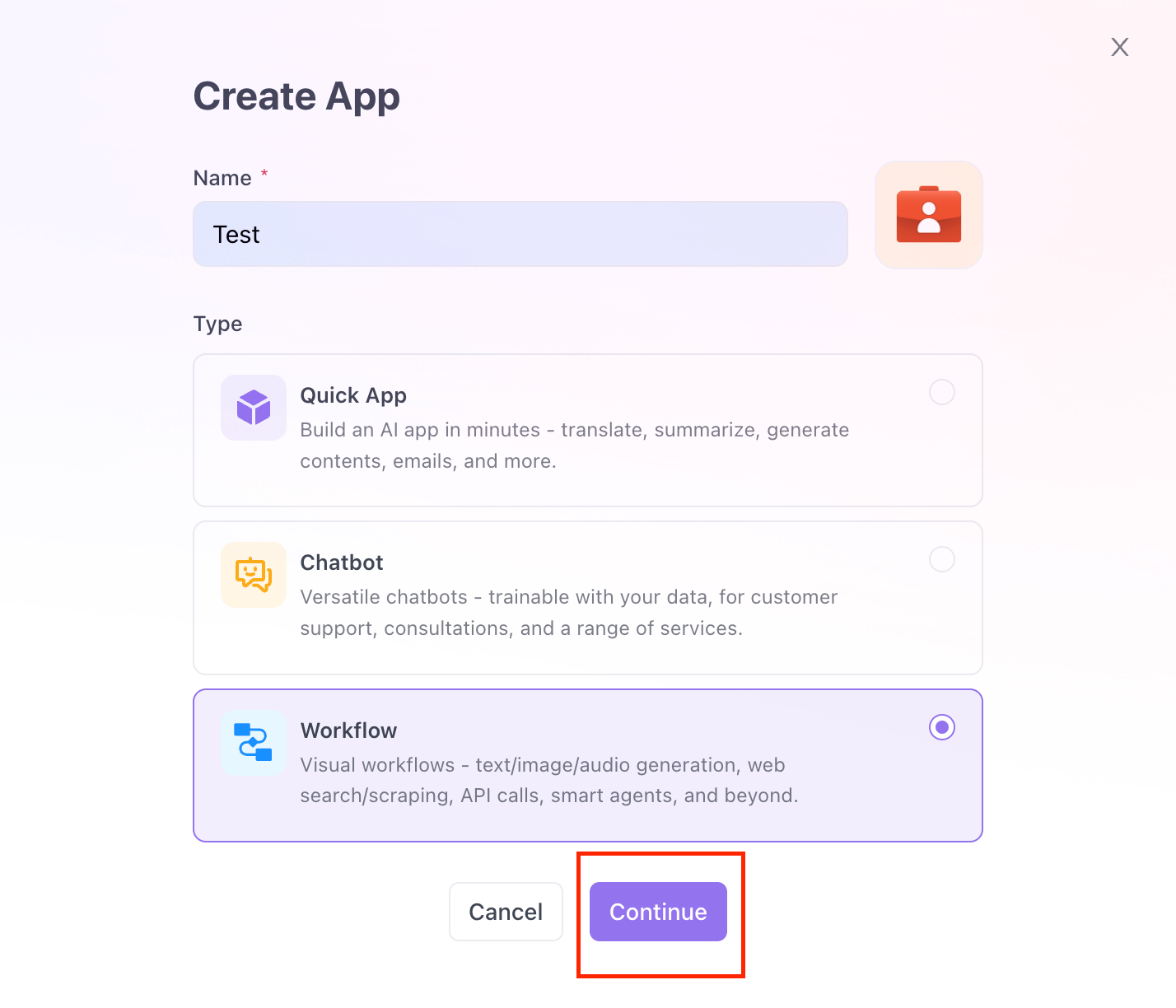
Click on the "Create New App" button to start building your app.
Then, you can Name your app, choose the Workflow option, and click on the Continue button.
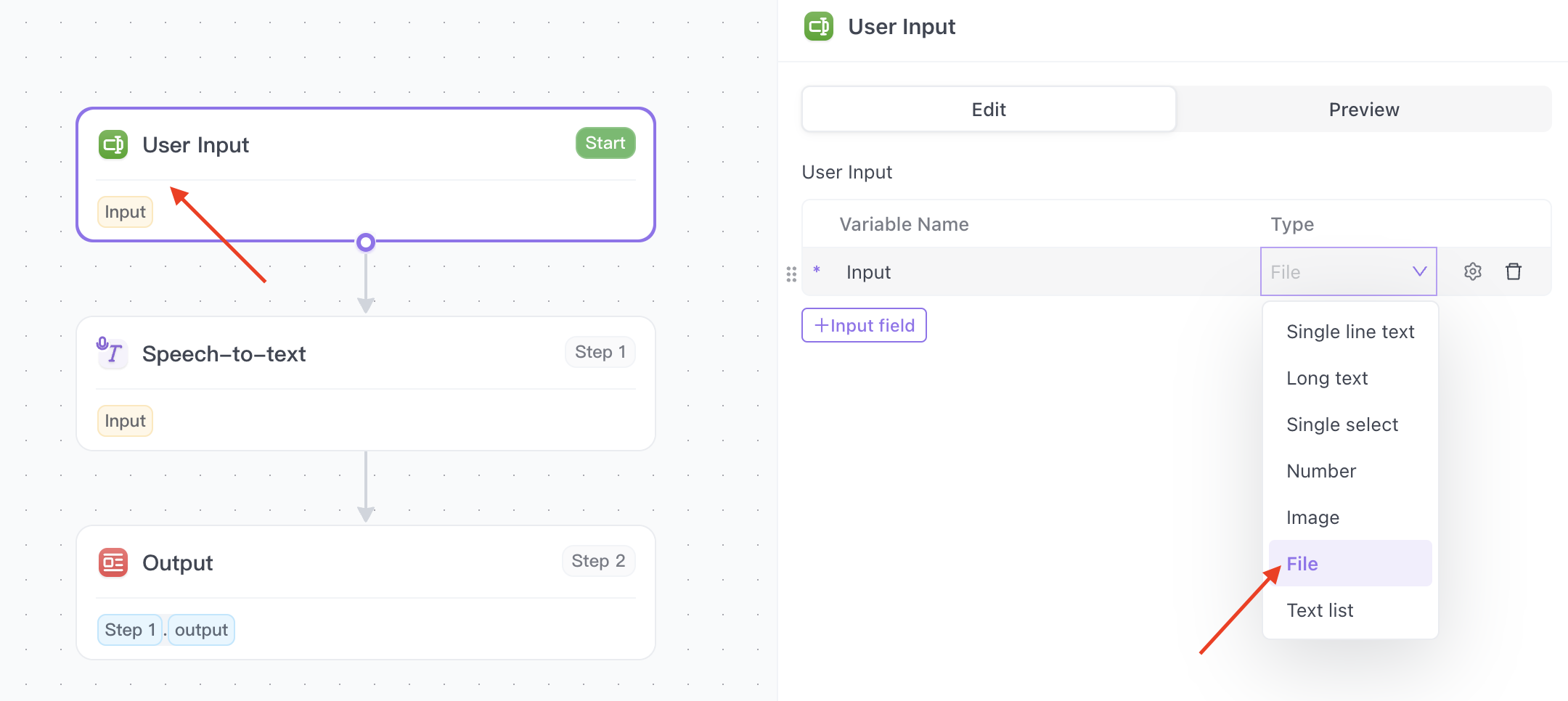
Step 2. Modify User Input
You need to ensure that the user of the app is able to upload an audio file.
Click on the User Input step.
On the panel on the right side of the screen, click on the dropdown menu in the "Type" Column, and select the File option.
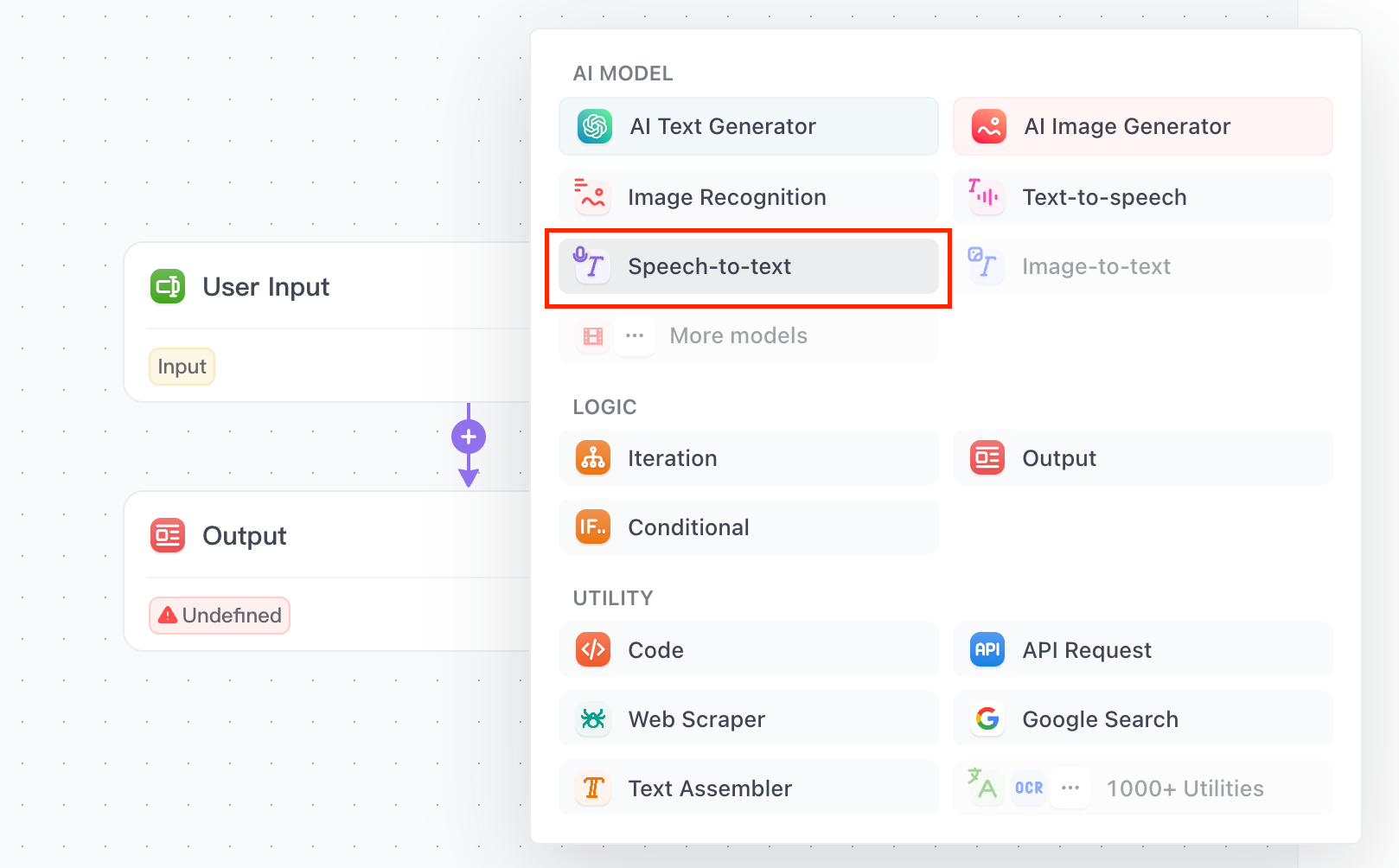
Step 3: Add Whisper API to Your App
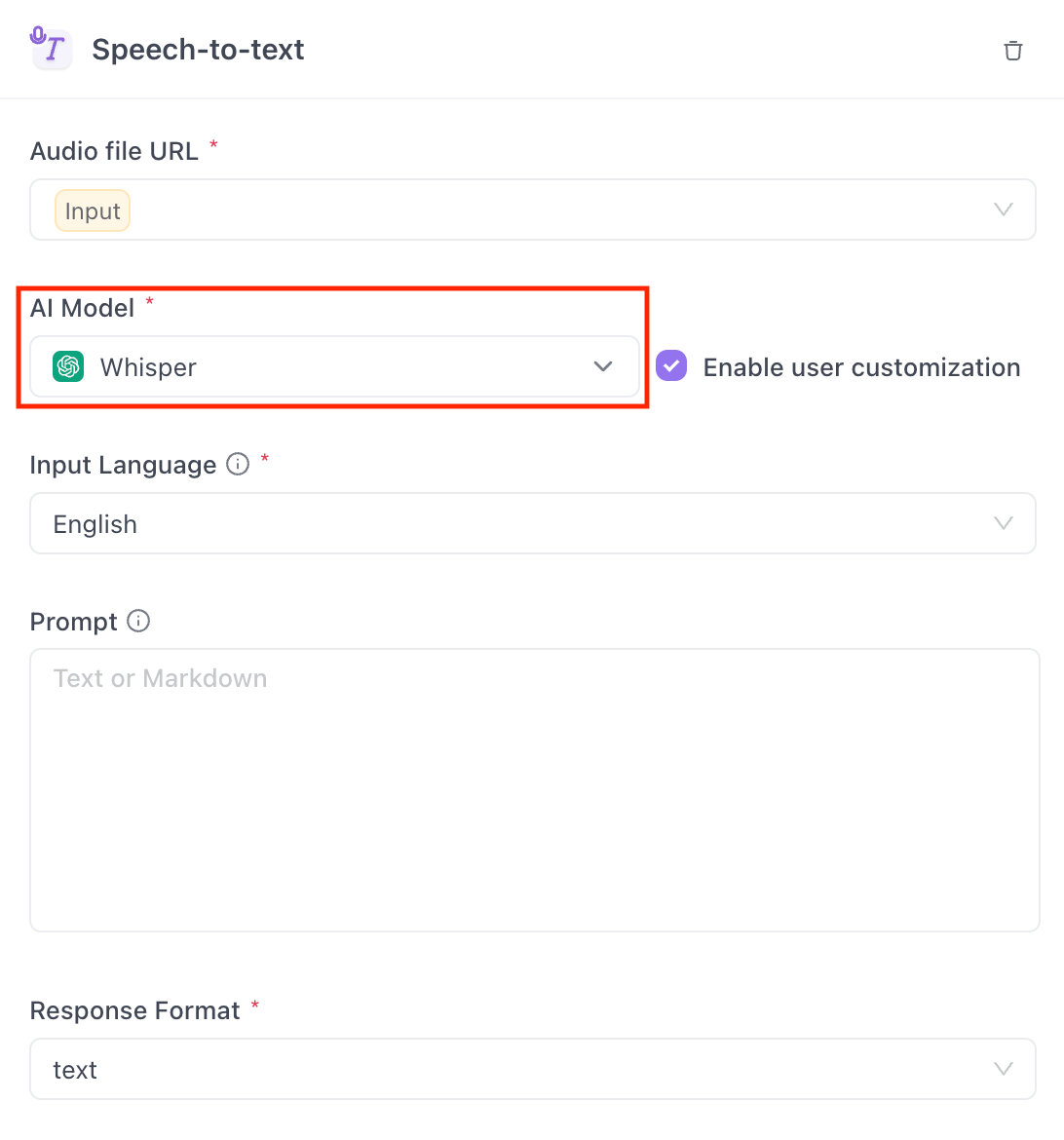
In the app builder, click on the Add Step button, and choose Speech-to-text option.
On the right side of the panel, you can select Whisper as your AI model!
Step 4: Build Your App
Customize the workflow of your app as needed. You can connect Whisper ASR to other modules or services in your app.
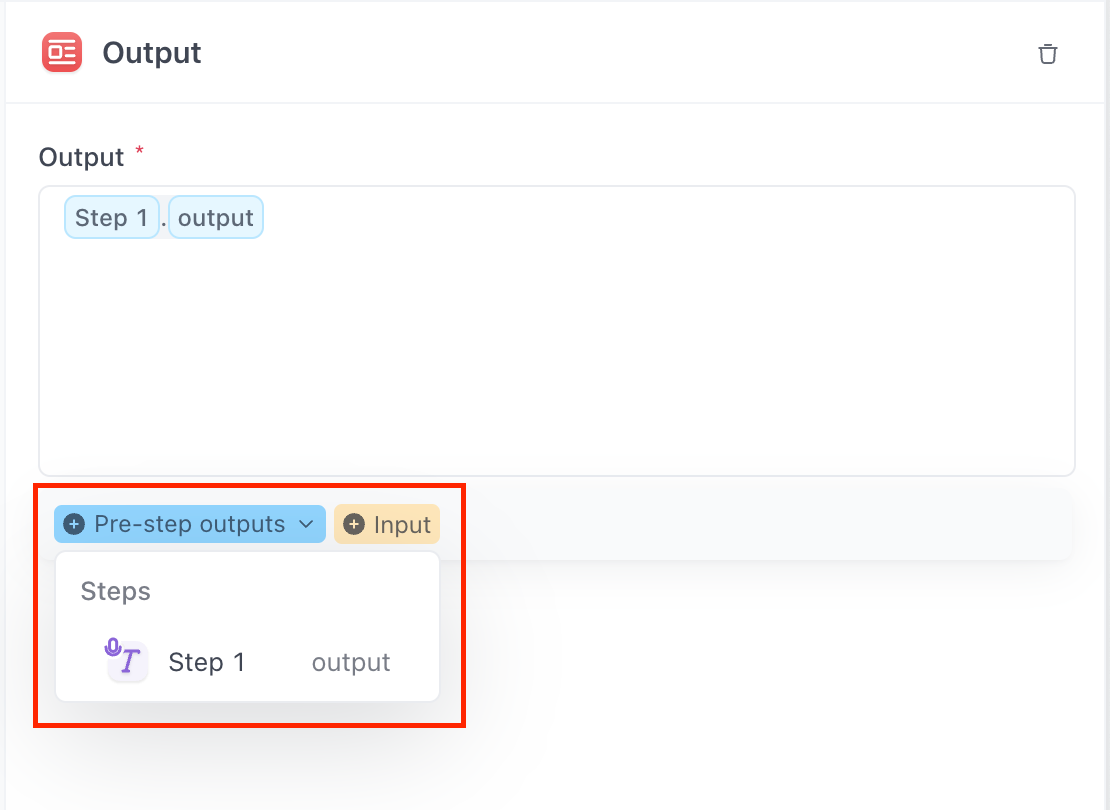
Do not forget to select the Whisper as the output file in the Output step!
Step 4: Test and Save Your App
Click on the Test tab to test your app.
Once satisfied, Do Not Forget to click on the Save to workspace button to save it!
Using Anakin AI's No Code App Builder, you can easily create customized apps that leverage OpenAI Whisper for speech-to-text transcription without the need for coding expertise. This method is ideal for users who prefer a straightforward approach to utilizing Whisper.
Ensure that you have an active OpenAI account to access Whisper. If you don't have one, sign up on the OpenAI website and generate an API key.
Step 3: Run Whisper
Once Whisper is installed, you can run it from the command line to transcribe speech into text. Use the following command, replacing your_api_key with your actual OpenAI API key:
For optimal performance, it's recommended to run Whisper on a GPU for applications requiring larger, more powerful versions of Whisper.
Keep in mind that there are different versions of Whisper available, such as "large" and "medium," each with its own capabilities and requirements.
By following these manual installation and usage steps, you can effectively use OpenAI's Whisper for speech-to-text transcription, giving you more control and flexibility over the process.
How to Improve the Accuracy of OpenAI Whisper
In the previous section, we explored two methods of using OpenAI Whisper for speech-to-text transcription. Now, let's dive into the crucial aspect of enhancing the accuracy of your transcriptions. While Whisper is a powerful tool, there are several strategies you can employ to ensure that the transcribed text is as precise as possible.
Utilize Different Models
OpenAI offers various Whisper models, such as small, medium, and large, each with its own set of capabilities. The choice of model can significantly impact the accuracy of your transcriptions.
Step 1: Choose the Right Model
Assess your transcription needs. If you require higher accuracy, consider using the "large" model.
Keep in mind that larger models may consume more processing resources, so ensure your hardware can support it.
Consider "faster-whisper" Project
The "faster-whisper" project is an exciting development that implements the OpenAI Whisper model in CTranslate2, resulting in significantly reduced transcription times.
Step 2: Implement "faster-whisper"
Visit the "faster-whisper" GitHub repository (https://github.com/iwat/fast-whisper) for instructions on how to implement this optimized version.
Follow the provided guidelines to set up and run "faster-whisper" for faster and efficient transcription.
Fine-Tuning for Specialized Tasks
Fine-tuning the Whisper model on specific datasets or languages can substantially improve its performance for specialized tasks. Hugging Face, a popular platform for natural language processing, provides discussions and examples on how to fine-tune the Whisper model for specific use cases.
Step 3: Explore Fine-Tuning
Visit the Hugging Face website (https://huggingface.co/) and navigate to the Whisper model page.
Explore the available resources and tutorials on fine-tuning Whisper for your specific transcription needs.
Follow the guidelines to fine-tune the model effectively.
Optimize Hardware
Hardware optimization plays a crucial role in improving the performance and accuracy of Whisper, especially for larger models.
Step 4: Upgrade Hardware
Consider upgrading your hardware, such as using GPUs (Graphics Processing Units), to significantly enhance the performance of Whisper.
Verify that your hardware meets the requirements of the chosen Whisper model.
By considering these approaches, you can work towards improving the accuracy of OpenAI Whisper for your specific use case. Whether you need precise transcriptions for research, content creation, or any other application, these strategies will help you achieve more accurate results.
Understanding the Limitations of OpenAI Whisper
While OpenAI Whisper is a versatile and powerful tool for speech-to-text transcription, it does have certain limitations that users should be aware of. Understanding these limitations is crucial for managing expectations and addressing potential challenges.
File Size Limit
Whisper imposes a 25 MB limit on the size of the audio file that can be transcribed. If the file exceeds this limit, the model will return an error, prompting the user to submit a smaller file.
Training Data Dependency
As a machine learning model, Whisper's performance may be affected when encountering data it hasn't been trained on. This can lead to reduced accuracy when dealing with untrained data or dialects.
API Rate Limits
The Whisper API has rate limits in place to ensure fair usage. As of the latest information available, the rate limit is set at 50 requests per minute, with a low limit on concurrent requests per minute. Users should be mindful of these limits when planning their transcription tasks.
Known Failure Modes
Whisper has known failure modes that developers need to handle. These include issues with silent segments, repetition in the output, and hallucinations (the model generating content that was not present in the original audio). These errors can be critical in certain automatic speech recognition (ASR) use cases, such as compliance, finance, healthcare, and legal services.
Real-World Applications of OpenAI Whisper
Despite its limitations, OpenAI Whisper finds its place in a wide range of real-world applications:
Healthcare
Transcribing medical dictations, ensuring accurate and concise patient records.
Legal Services
Documenting court proceedings, depositions, and client interviews for legal documentation.
Finance
Analyzing and transcribing financial conference calls, earnings reports, and investor meetings.
Education
Creating accessible lecture transcripts, making educational content more inclusive.
Content Creation
Converting podcast episodes, interviews, and video content into written articles and captions.
The versatility of Whisper makes it a valuable asset in various professional settings, streamlining transcription tasks and enhancing productivity.
Best Practices for Using OpenAI Whisper
To make the most of OpenAI Whisper, consider these best practices:
Data Preparation
Ensure that your audio data is of high quality and properly formatted to improve transcription accuracy.
API Rate Limit Management
Be mindful of the rate limits imposed by the Whisper API and plan your transcription tasks accordingly.
Model Selection
Choose the appropriate Whisper model (small, medium, or large) based on your accuracy and processing power requirements.
Quality Verification
Review and verify the transcribed text for accuracy, especially for critical applications.
Conclusion
OpenAI Whisper stands as a powerful solution for speech-to-text transcription, revolutionizing how we convert spoken language into written text. Its applications are vast, spanning from healthcare to finance, and its potential is undeniable.
In this comprehensive guide, we've explored how to get started with Whisper, improve its accuracy, understand its limitations, and apply it to real-world scenarios. By following best practices and being aware of its capabilities, you can harness the full potential of OpenAI Whisper in your professional and personal endeavors.
As the demand for accurate and efficient transcription continues to grow, OpenAI's Whisper remains a reliable partner, simplifying the task of converting speech into text and opening up new possibilities in the world of content creation, accessibility, research, and more.
Unlock the power of Whisper, and start transcribing with confidence today.